 Sign in
Sign in
iow_20120329 - Gaia
![]()
Image of the Week |
GREAT school results |
 |
|
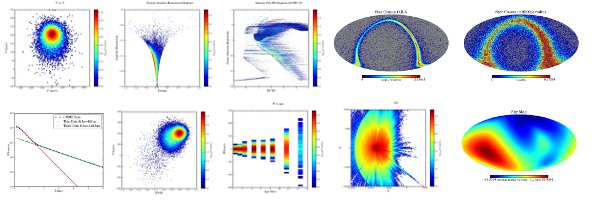
Earlier this year in the week of January 23 the GREAT School on the Science and Techniques of Gaia, organized by the GREAT Initial Training Network, was held at the Lorentz Center in Leiden. The school was intended for the ITN PhD students, most of whom had just started their PhD research, and a number of students from outside the network were also invited. The school consisted of morning lectures, treating the major Gaia science topics that are covered by the GREAT ITN, and afternoon exercises aimed at giving the students a flavour of what it will be like to work with the huge Gaia catalogue. The exercises consisted of exploring various aspects of the simulated data contained in the Gaia Universe Model Snapshot version 10 (described here). The students worked in groups on exercises which involved interrogating the GUMS data set in order to research various aspects of the structure and dynamics of the Milky Way. GUMS contains 1.6 billion stars and represents a non-trivial data set to work with. For these exercises the students used a custom developed Java framework based on Hadoop, provided to them on a virtual machine (containing a small subset of the GUMS data set) which they installed on their notebooks. The virtual machine and Hadoop framework were prepared by Daniel Tapiador and William O'Mullane at ESAC. For the exercise groups that managed to get their code working quickly there was the opportunity to run the code against the full GUMS data set which was stored in 'the cloud' at Amazon. This provided a taste of the future possibility of 'bringing the processing to the data'. The pictures above show the results obtained by the students:
[Published: 29/03/2012] |
- Removed a total of (3) style text-align:center;
- Removed a total of (4) style text-align:justify;
- Removed a total of (1) border attribute.
- Removed a total of (1) cellpadding attribute.
- Removed a total of (1) cellspacing attribute.
Image of the Week Archive
- Removed a total of (1) border attribute.
- Removed a total of (1) cellpadding attribute.
- Removed a total of (1) cellspacing attribute.